Appendix A — FAQ
General
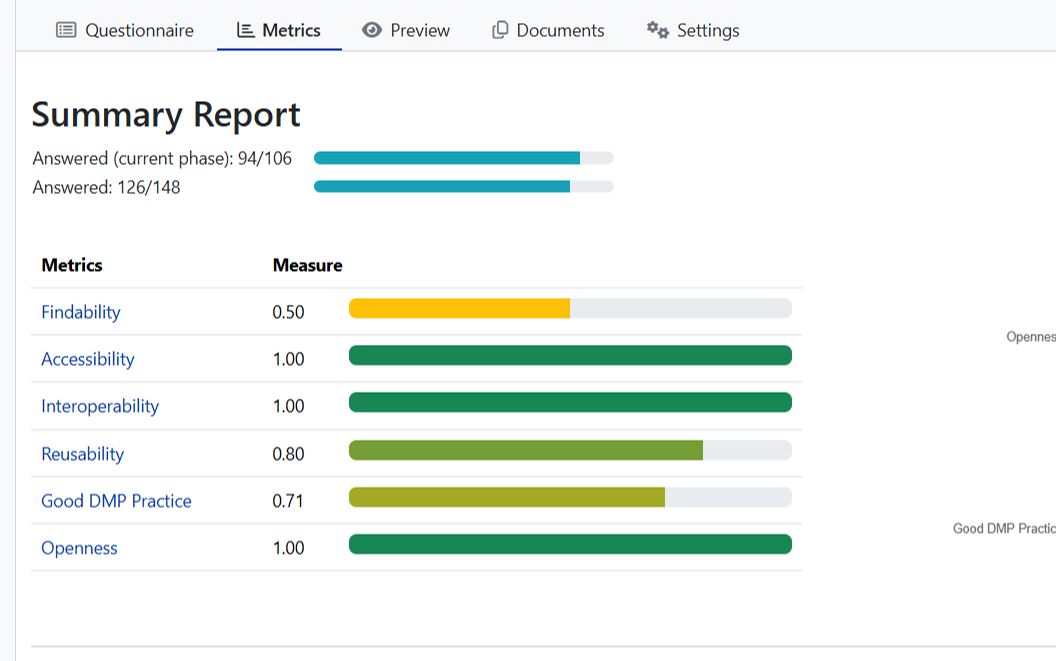
NoteWhat does the “Metrics” tab show?
Some of the responses in the DMP are used by the WP7 team to capture whether the responses in the DMP are sufficient to ensure that FAIR data is planned to be achieved. For example, the data being reported in PARC data reporting templates would give a FAIRness score. Note that the DMP is just a plan, and it is only when the actions described in the DMP are actually implemented by the data-generating partners in the project that the data is actually FAIR. Implementation of the DMP is verified by the project managers. The metrics cover the Findability of Data, the Accessibility of Data etc.
DMP Questions
I. Administrative information
II. Re-using data
III. Creating and collecting data
IV. Processing data
V. Interpreting data
VI. Preserving data
VII. Giving access to data
ImportantMy question is not in this list and I need help
Please contact the WP7 DMP Team by clicking the icon on the top-left (below the PARC logo), or by clicking WP7 DMP Troubleshooters.